图文并茂:DeepSeek R1 是怎么练成的?
作者:江信陵,为AI发电

图片来源:由无界AI生成
DeepSeek 是如何训练其 R1 推理模型的?本文主要基于DeepSeek发布的技术报告,解读 DeepSeek - R1 的训练过程;重点探讨了构建和提升推理模型的四种策略。
原文来自研究员 Sebastian Raschka,发表于:
https://magazine.sebastianraschka.com/p/understanding-reasoning-llms
本文会对其中R1推理模型核心训练部分进行总结。
首先,基于DeepSeek发布的技术报告,以下是一张R1的训练图。
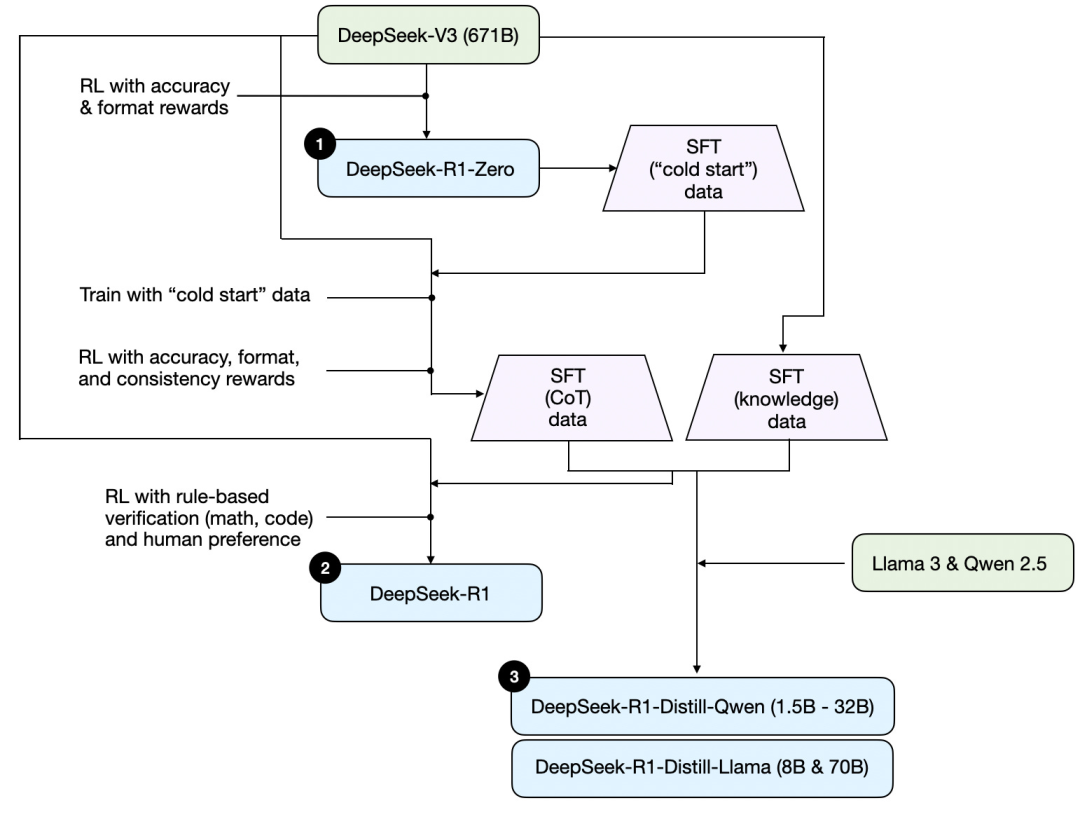
梳理一下上图所示的过程,其中:
(1) DeepSeek - R1 - Zero:该模型是基于去年 12 月发布的 DeepSeek - V3 基模。使用具有两种奖励机制的强化学习(RL)对其进行训练。这种方法被称为 “冷启动” 训练,因为它不包括监督微调(SFT)步骤,而监督微调通常是人类反馈强化学习(RLHF)的一部分。
(2) DeepSeek - R1:这是 DeepSeek 的主打推理模型,基于 DeepSeek - R1 - Zero 构建。团队通过额外的监督微调阶段和进一步的强化学习训练对其进行了优化,改进了 “冷启动” 的 R1 - Zero 模型。
(3) DeepSeek - R1 - Distill:DeepSeek 团队利用前几步生成的监督微调数据对 Qwen 和 Llama 模型进行了Fine Tuning,以增强它们的推理能力。虽然这并非传统意义上的蒸馏,但该过程涉及到利用较大的 671B的 DeepSeek - R1 模型的输出对较小的模型(Llama 8B 和 70B,以及 Qwen 1.5B - 30B)进行训练。
以下会介绍构建与提升推理模型的四种主要方法
1、推理时扩展 / Inference-time scaling
提升 LLM 推理能力(或通常意义上的任何能力)的一种方法是推理时扩展 - 在推理过程中增加计算资源,以提高输出质量。
打个粗略的比方,就像人在有更多时间思考复杂问题时,往往能给出更好的回答。同样,我们可以运用一些技术,促使 LLM 在生成答案时 “思考” 得更深入。
实现推理时扩展的一种简单方法是巧妙的提示工程 / Prompt Engineering。一个经典例子是思维链提示 / CoT Prompting,即在输入提示中加入诸如 “逐步思考” 这样的短语。这会促使模型生成中间推理步骤,而不是直接跳到最终答案,这样往往能在更复杂的问题上得出更准确的结果。(注意,对于像 “法国的首都是什么” 这类较简单的基于知识的问题,采用这种策略就没有意义,这也是判断推理模型对于给定输入查询是否适用的一个实用经验法则。)

分享链接: - 区块链日报
免责声明:本站所有内容不构成投资建议,币市有风险、投资请慎重。