让 AI 编程去干活能挣到 40 万美元?
作者:谭梓馨,头部科技

图片来源:由无界AI生成
大型语言模型 (LLM)正在改变软件开发方式,AI现在能不能大规模替代人类程序员成为一个备受行业关注的话题。
在短短两年时间里,AI大模型已经从解决基础计算机科学问题,发展到在国际编程竞赛中与人类高手一较高下的程度,例如OpenAI o1曾在与人类参赛者相同的条件下参加2024国际信息学奥林匹克竞赛(IOI)并成功获得金牌,展现了强大的编程潜力。
同时,AI迭代速率也在加快。在代码生成评估基准SWE-Bench Verified上,2024年8月GPT-4o的得分是33%,但到了新一代o3模型得分已翻倍为72%。

为了更好衡量AI模型在现实世界中的软件工程能力,今天,OpenAI开源推出了一个全新的评估基准SWE-Lancer,首次将模型性能与货币价值挂上了钩。
SWE-Lancer是一个包含1400多个来自Upwork平台自由软件工程任务的基准测试,这些任务在现实世界中的总报酬价值约100万美元,让AI去编程能挣到多少钱?
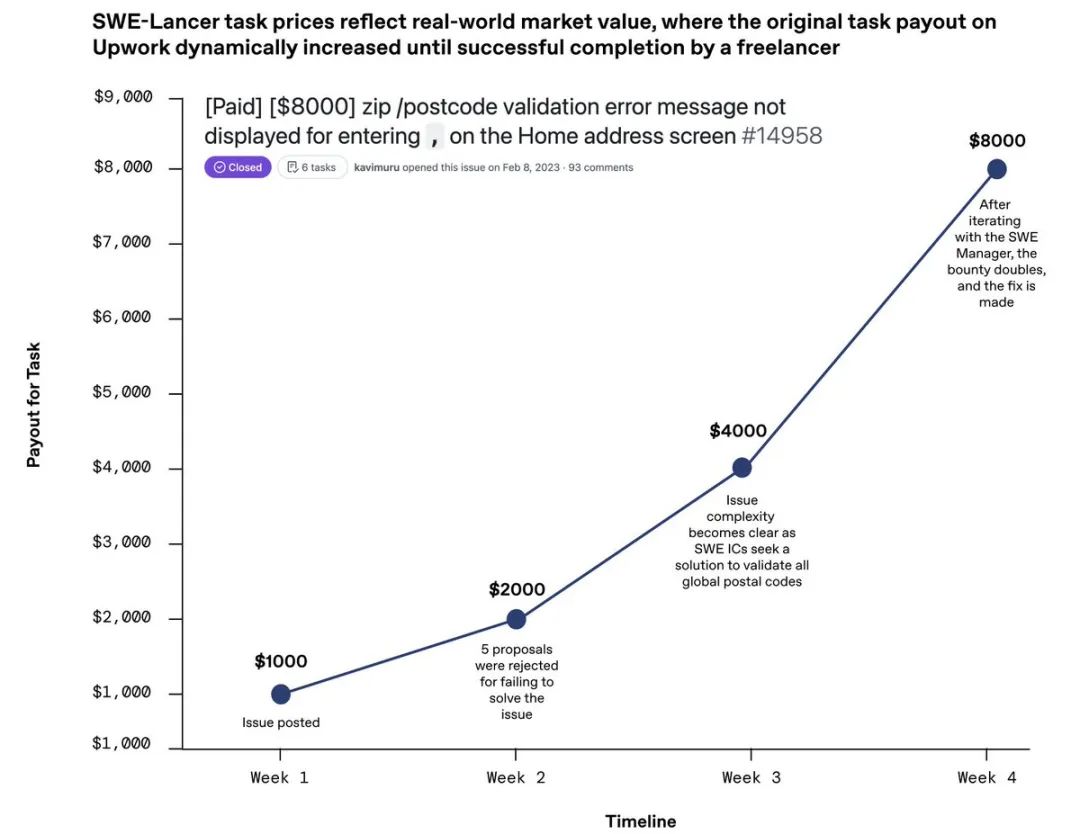
新基准的“特色”SWE-Lancer基准任务价格反映真实的市场价值情况,任务越难,报酬越高。
其中既包括独立工程任务,也包括管理任务,可在技术实施方案之间进行选择,该基准不仅针对程序员,也针对整个开发团队,包括架构师和管理人员。
相较于此前的软件工程测试基准,SWE-Lancer具有多项优势,例如:
1、全部1488个任务代表了雇主向自由工程师支付的真实报酬,提供了自然的、由市场决定的难度梯度,报酬从250美元到3.2万美元不等,可谓相当可观。
其中35%的任务价值超过1000美元,34%的任务价值在500美元到1000美元之间。个体贡献者(IC)软件工程(SWE)任务这一组包含了764个任务,总价值41.4775万美元;SWE管理任务这一组包含724个任务,总价值58.5225万美元。
2、现实世界中的大规模软件工程,不仅需要具体敲代码可开发,还需要有能力的技术统筹管理,该基准测试使用真实世界的数据评估模型充当SWE“技术主管的”角色。
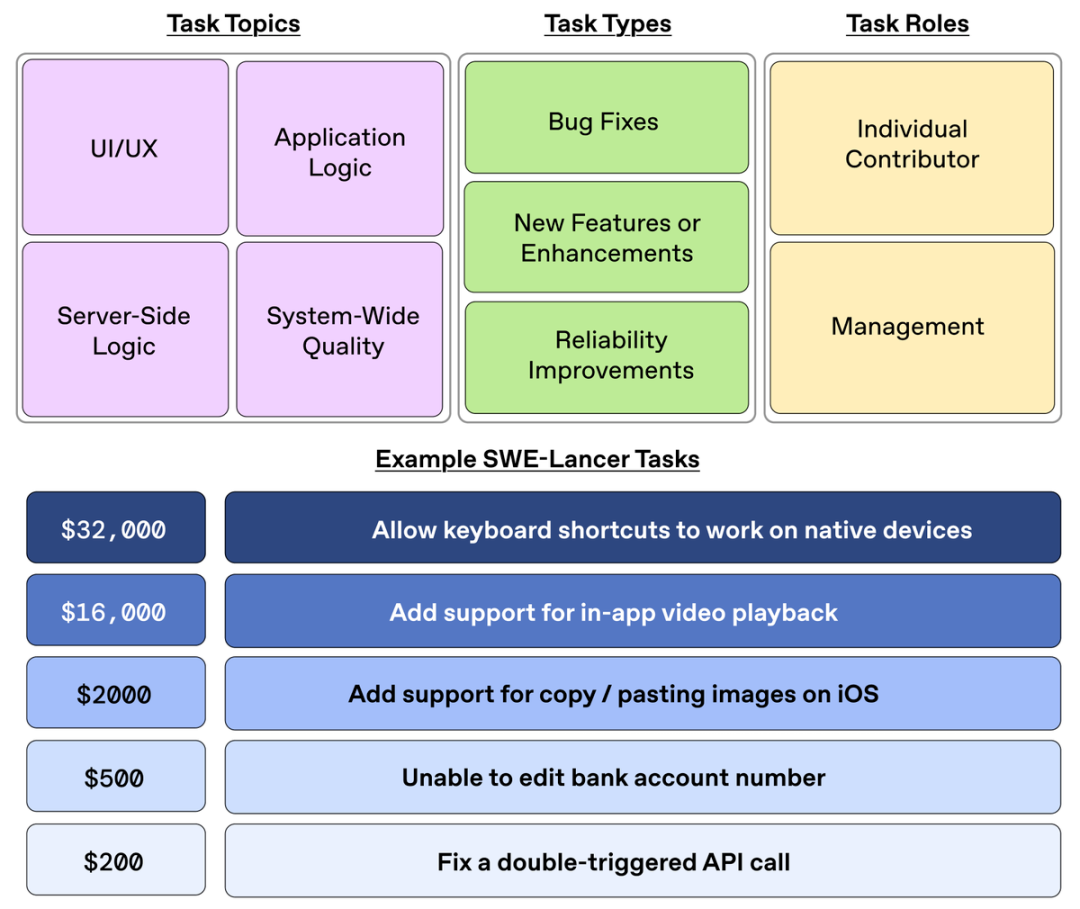
3、具备高级全栈工程评测能力。SWE-Lancer代表现实世界的软件工程,因为其任务来自拥有数百万真实用户的平台。
其中的任务涉及移动和网页端的工程开发、与API、浏览器和外部应用程序的交互,以及复杂问题的验证和复现。
分享链接: - 区块链日报
免责声明:本站所有内容不构成投资建议,币市有风险、投资请慎重。