DeepSeek 利润神话背后:大厂 AI 的焦虑和自救
作者:王璐

图片来源:由无界AI生成
AI似乎成了大厂的“救命稻草”。
无论财报里的亮点数据,还是隔三岔五的利好信息,都离不开AI。
比如在百度2024年这份喜忧参半的财报中,高光时刻基本都是AI给的:
文心大模型日均调用量持续高速增长,一年增长33倍至16.5亿。百度文库付费用户超4000万,位居全球第二、中国第一。
阿里也凭借着AI在开年来了三连击:
先是受DeepSeek影响,同为开源大模型的阿里通义千问(Qwen)受到关注;接着发布的最新模型Qwen2.5-Max,被评价为性能超越DeepSeek V3;随后又宣布与苹果就AI业务达成合作,股价猛涨。
不过,DeepSeek出圈近40天以来,大厂AI承受的焦虑多过收获,毕竟各家都投入了大量人力、物力、财力,最后一鸣惊人的却是一个初创团队做出的产品。这两天,DeepSeek还首次公开了爆炸性消息——其成本利润率高达545%(理论收益),利润理论上可达每天346万元。
在种种冲击之下,大厂纷纷改变路线,一边打不过就加入,纷纷宣布接入DeepSeek,一边将自家大模型从闭源转向开源,甚至不惜自断一条商业化路径,将C端产品免费。
可是,这波操作,真能治好大厂的AI焦虑症吗?
大厂AI,做得怎么样了?在DeepSeek出现前,大厂做AI的路线是高举高打、重投入,围绕自身优势做产品。
大模型被视为AI行业的基础设施,互联网大厂(百度、腾讯、阿里、字节、快手等)、消费电子厂商(华为为代表)、智能语音厂商(科大讯飞等),都推出了自研大模型。相比“AI六小虎”这类初创公司,大厂的优势在于具备更雄厚的资金和人才储备。
从AI行业整体技术迭代速度,以及各家的公开信息来看,大厂大模型在底层技术上没有根性本差别,但在入场时间、模型定位、市场策略上有所不同,具体区别如下:
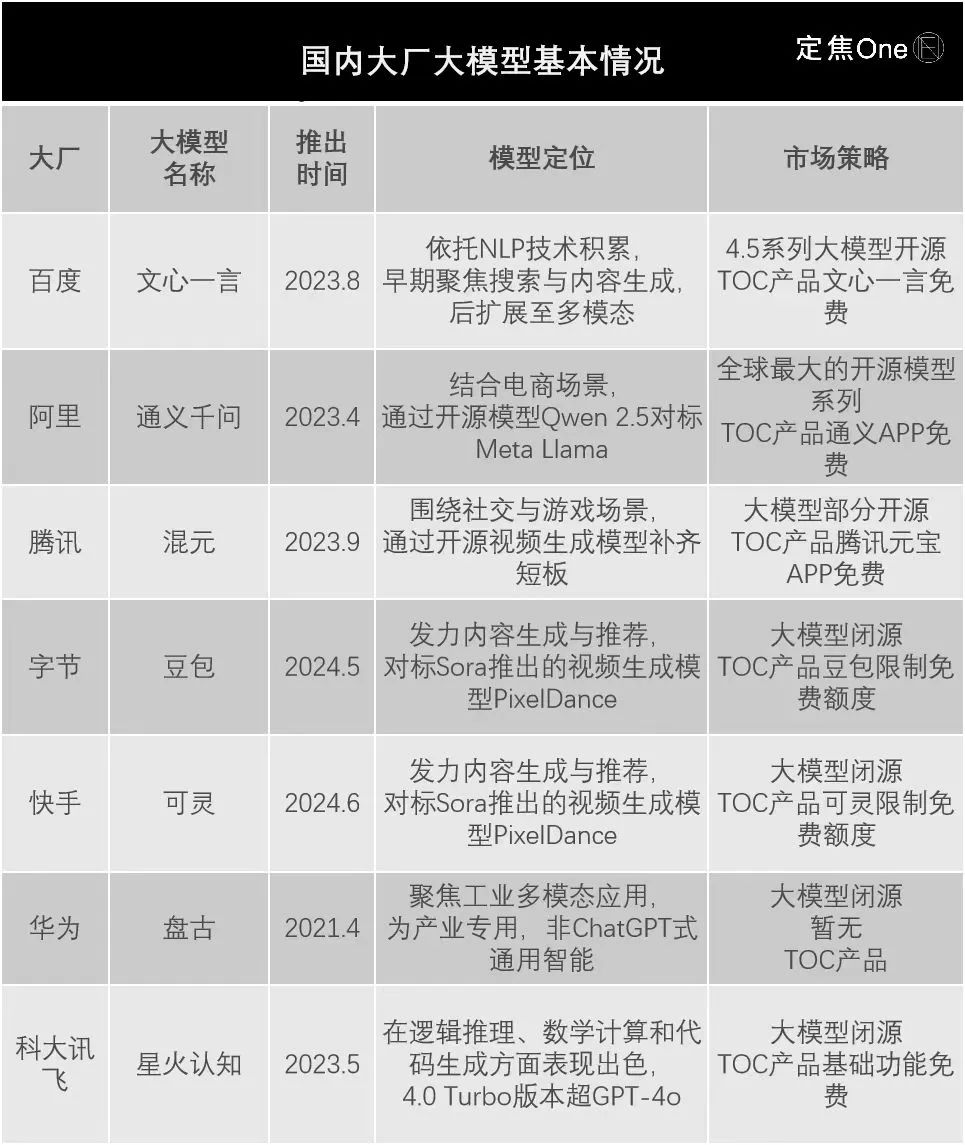
这三大不同,在一定程度上代表的是大厂早期对AI的态度和定位。
比如大模型发布的时间,“早”代表的是该大厂在相关技术领域有较早布局和技术积累,且反应较快,但风险是技术尚未完全成熟,投入的技术研发和市场推广费用相对更高。
从上表来看,华为最早,但需要注意的是,虽然其底层也是基于Transformer架构,但与ChatGPT式对话完全不同,属于AI大模型在“产业专用”方向(ChatGPT式为通用智能)。如果聚焦通用智能大模型,则是百度最早行动,在2023年3月便启动了文心一言大模型的邀测(非全面开放)。
分享链接: - 区块链日报
免责声明:本站所有内容不构成投资建议,币市有风险、投资请慎重。