杨植麟和梁文锋,论文撞车了
一
在马斯克发布了他用20万张卡训出的Grok3的同一天,两篇与马氏大力出奇迹“相反”路线的论文也发表在了技术社区。
在这两篇论文的作者名目里,各自有一个大家熟悉的名字:
梁文锋,杨植麟。


2月18日,DeepSeek和月之暗面几乎同时发布了他们各自最新的论文,而主题直接“撞车”——都是挑战Transformer架构最核心的注意力机制,让它能更高效的处理更长的上下文。而更有趣的是,两家公司的技术派明星创始人的名字出现在各自的论文和技术报告里。
DeepSeek 发布的论文,标题名为:《Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention》。
根据论文,它提出的新架构NSA(原生稀疏注意力)在基准测试中,与全注意力机制相比,准确率相同或更高;处理 64k 标记序列时,速度可提高至 11.6 倍,训练也更高效,所需算力更少;在处理超长上下文的任务(如书籍摘要、代码生成、推理任务)中表现出色。
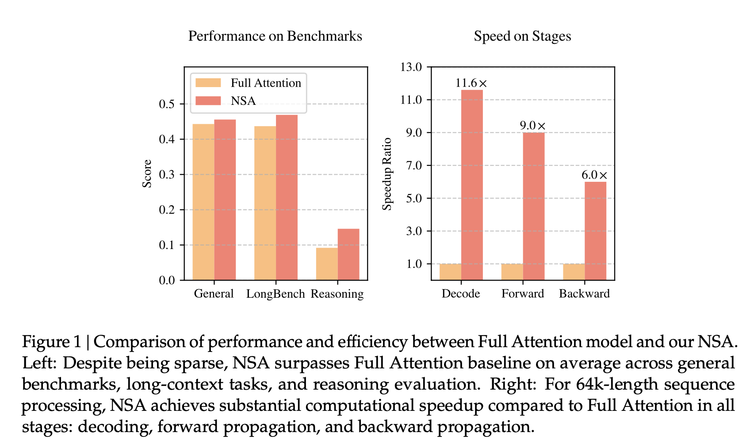
与此前人们津津乐道的算法上的创新相比,DeepSeek这一次把手伸向了最核心的注意力机制(attention)的改造上。
Transformer是今天所有大模型繁荣的基础,但它的核心算法注意力机制依然有先天的问题:拿读书做比喻,传统的“全注意力机制”为了理解和生成,会阅读文本里的每个词,并拿它与其他所有词作比较。这样导致处理文本越长它越复杂,技术越卡,甚至崩溃。
此前学术界一直在提供各种解决的思路,NSA通过真实环境的工程优化和实验,组装出了一个由三个环节组成的可以用在训练阶段的架构方案:
它包括,1)语义压缩——不再是看每个词,而是分成一个组,也就是“块”,在保留全局语义的同时将序列长度缩减至1/k,同时引入位置编码来降低信息的损耗,进而将计算复杂度从O(n²)降为O(n²/k)。
2)动态选择——模型以某种得分判断机制,从文本中挑出最多关注的词,对它们进行细粒度的计算。这种重要性采样策略在减少75%计算量的情况下仍能保持98%的细粒度信息。
3)滑动窗口——前两者是摘要和划重点的话,滑动窗口就是查看最近的上下文信息,这样可以保持连贯性,而通过硬件级显存复用技术可以将内存访问频次降低40%。
这些思路每一个都不是DeepSeek的发明,但可以把它想象成ASML式的工作——这些技术元素已经存在,散落在各处,但工程上把它们组合在一起成为一个可以规模化的方案,新的算法架构,还没人做过。现在有人通过强大的工程能力做出来了一台“光刻机”,其他人可以用这个来在真实工业环境里训练模型。
分享链接: - 区块链日报
免责声明:本站所有内容不构成投资建议,币市有风险、投资请慎重。